Sample Classification Predictions
Classification Information in Scores Plot
It is possible to view results of predicting classification of X-block samples in the Scores Plot when using analysis methods PLSDA, SVMDA, KNN or SIMCA, after the model has been built. If the model has been applied to test data then predictions will also be available for the test data. The predictions for the calibration data are self-predictions of the model on the calibration data.
These analysis methods determine the probability that a sample belongs to each possible classes. Based on this the user can view plots showing the most probable class of each sample according to the model predictions. The "Plot Controls" window for the scores plot shows several classification fields among the choices of X or Y fields to plot. For example, setting the Plot Controls X field = "Sample" and the Y field = "Class Pred Most Probable" will show the most probable class for each sample in the Scores Plot.
In this "Class Pred Most Probable" case the Y axis ranges over class numbers and a sample belonging to class = 2 is shown at (x,y) = (sample number, 2). Points are drawn with distinct symbols for each class and inserting a figure legend shows the class ID associated with each symbol.
There is always a most likely class for a sample to belong to but it is possible that the sample is not well modeled and has low probabilities for all classes. Or it is possible that two classes are similar and a sample belonging to one of them will also have a high predicted probability of belonging to the second class too. In these situations there can be little confidence in the "most probable" class prediction. The choice labeled "Class Pred Strict" addresses these situations by assigning the sample to the "unknown" class (zero) if the most likely class probability is less than 0.5 or if two or more classes have probability of greater than 0.5 for the sample.
The predicted probability that a sample belongs to a particular class, for example the class named <classID>, is available under the label "Class Pred Probability <ClassID>". A sample belonging to this class will have value = 1, or 0 otherwise.
The label "Class Pred Member <ClassID>" identifies samples which have predicted probability > 0.5 of belonging to class "<ClassID>". These samples will have value = 1, or 0 otherwise. Note that label "Class Pred Member - unassigned" identifies samples which were not assigned to any class because no predicted probability was greater than 0.5.
Finally, label "Misclassified" identifies samples where the predicted "Class Pred Strict" does not agree with the sample's actual class. For SIMCA and PLSDA the actual class could include more than one class and the sample is misclassified if its "Class Pred Member <ClassID>" do not correctly predict the actual class(es). If the sample's actual class is unknown then the sample will not be identified as as misclassified.
Example of Classification Information in Scores Plot
Shown below is an example Scores Plot from PLSDA run on the arch dataset. In the Plot Controls window (on left) are shown some of the classification fields which may be plotted. The X field is set to "Sample" and the Y field is set to "Misclassified". The Scores Plot shows that all X samples have value 0 (NOT misclassified) except for one sample, the 16th, which has value 1, indicating it is misclassified. Looking at the "Class Pred Most Probable" field shows this sample is correctly predicted as belonging to class 2 ("BL"). Looking at "Class Member Pred K" and "Class Member Pred BL" both show sample 16 belonging, meaning that sample 16 belongs to each of these classes with probability > 0.5. Sample 16 actually only belongs to class "BL" as shown by Y="Class Measured 2 (BL)", and therefore it is considered to be misclassified.
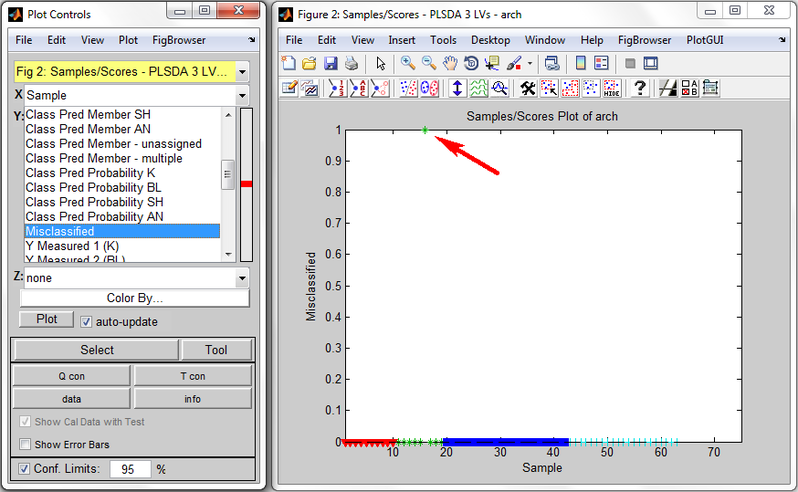
Scores Plot (right) and its Plot Controls (left) for PLSDA on arch dataset.
