Svmda
Purpose
SVMDA Support Vector Machine (LIBSVM) for classification.
Synopsis
- model = svmda(x,y,options); %identifies model (calibration step)
- pred = svmda(x,model,options); %makes predictions with a new X-block
- pred = svmda(x,y,model,options); %performs a "test" call with a new X-block and known y-values
Description
SVMDA performs calibration and application of Support Vector Machine (SVM) classification models. (Please see the svm function for support vector machine regression problems). These are non-linear models which can be used for classification problems. The model consists of a number of support vectors (essentially samples selected from the calibration set) and non-linear model coefficients which define the non-linear mapping of variables in the input x-block to allow prediction of the classification as passed in either as the classes field of the x-block or in a y-block which contains integer-valued classes. It is recommended that regression be done through the svm function.
Svmda is implemented using the LIBSVM package which provides both cost-support vector regression (C-SVC) and nu-support vector regression (nu-SVC). Linear and Gaussian Radial Basis Function kernel types are supported by this function.
Note: Calling svmda with no inputs starts the graphical user interface (GUI) for this analysis method.
Inputs
- x = X-block (predictor block) class "double" or "dataset", containing numeric values,
- y = Y-block (predicted block) class "double" or "dataset", containing integer values,
- model = previously generated model (when applying model to new data).
Outputs
- model = a standard model structure model with the following fields (see MODELSTRUCT):
- modeltype: 'SVM',
- datasource: structure array with information about input data,
- date: date of creation,
- time: time of creation,
- info: additional model information,
- pred: 2 element cell array with
- model predictions for each input block (when options.blockdetail='normal' x-block predictions are not saved).
- detail: sub-structure with additional model details and results, including:
- model.detail.svm.model: Matlab version of the libsvm svm_model (Java)
- model.detail.svm.cvscan: results of CV parameter scan
- model.detail.svm.outlier: results of outlier detection (one-class svm)
- pred a structure, similar to model for the new data.
- pred: The vector pred.pred{2} will contain the class predictions for each sample.
Options
options = a structure array with the following fields:
- display: [ 'off' | {'on'} ], governs level of display to command window,
- plots [ 'none' | {'final'} ], governs level of plotting,
- preprocessing: {[]} preprocessing structures for x block (see PREPROCESS). NOTE that y-block preprocessing is NOT used with SVMDA. Any y-preprocessing will be ignored.
- blockdetails: [ {'standard'} | 'all' ], extent of predictions and residuals included in model, 'standard' = only y-block, 'all' x- and y-blocks.
- algorithm: [ 'libsvm' ] algorithm to use. libsvm is default and currently only option.
- kerneltype: [ 'linear' | {'rbf'} ], SVM kernel to use. 'rbf' is default.
- svmtype: [ {'c-svc'} | 'nu-svc' ] Type of SVM to apply. The default is 'c-svc' for classification.
- probabilityestimates: [0| {1} ], whether to train the SVR model for probability estimates, 0 or 1 (default 1)"
- cvtimelimit: Set a time limit (seconds) on individual cross-validation sub-calculation when searching over supplied SVM parameter ranges for optimal parameters. Only relevant if parameter ranges are used for SVM parameters such as cost, epsilon, gamma or nu. Default is 10 (seconds);
- splits: Number of subsets to divide data into when applying n-fold cross validation. Default is 5.
- gamma: Value(s) to use for LIBSVM kernel gamma parameter. Default is 15 values from 10^-6 to 10, spaced uniformly in log.
- cost: Value(s) to use for LIBSVM 'c' parameter. Default is 11 values from 10^-3 to 100, spaced uniformly in log.
- nu: Value(s) to use for LIBSVM 'n' parameter (nu of nu-SVC, and nu-SVR). Default is the set of values [0.2, 0.5, 0.8].
- outliernu: Value to use for nu in LIBSVM's one-class svm outlier detection. A negative value disables outlier detection and it is disabled by default. It is enabled by setting outliernu to a positive value, for example outliernu=0.05.
Algorithm
Svmda uses the LIBSVM implementation using the user-specified values for the LIBSVM parameters (see options above). See [1] for further details of these options.
The default SVMDA parameters cost, nu and gamma have value ranges rather than single values. This svm function uses a search over the grid of appropriate parameters using cross-validation to select the optimal SVM parameter values and builds an SVM model using those values. This is the recommended usage. The user can avoid this grid-search by passing in single values for these parameters, however.
C-SVC and nu-SVC
There are two commonly used versions of SVM classification, 'C-SVC' and 'nu-SVC'. The original SVM formulations for Classification (SVC) and Regression (SVR) used parameters C [0, inf) and epsilon[0, inf) to apply a penalty to the optimization for points which were not correctly separated by the classifying hyperplane or for prediction errors greater than epsilon. Alternative versions of both SVM classification and regression were later developed where these penalty parameters were replaced by an alternative parameter, nu [0,1], which applies a slightly different penalty. The main motivation for the nu versions of SVM is that it has a has a more meaningful interpretation. This is because nu represents an upper bound on the fraction of training samples which are errors (misclassified, or poorly predicted) and a lower bound on the fraction of samples which are support vectors. Some users feel nu is more intuitive to use than C or epsilon. C/epsilon or nu are just different versions of the penalty parameter. The same optimization problem is solved in either case. Thus it should not matter which form of SVM you use, C versus nu for classification or epsilon versus nu for regression. PLS_Toolbox uses the C and epsilon versions since these were the original formulations and are the most commonly used forms. For more details on 'nu' SVMs see [2]
Class prediction probabilities
LIBSVM calculates the probabilities of each sample belonging to each possible class. The method is explained in [3], section 8, "Probability Estimates". PLS_Toolbox provides these probability estimates in model.detail.predprobability or predict.detail.predprobability, which are nsample x nclasses arrays. The columns are the classes, in the order given by model.detail.svm.model.label (or prediction.detail.svm.model.label), where the class values are what was in the input X-block.class{1} or Y-block. These probabilities are used to find the most likely class for each sample and this is saved in pred.pred{2} and model.detail.predictedclass. This is a vector of length equal to the number of samples with values equal to class values (model.detail.class{1}).
SVMDA Parameters
- cost: Cost [0 ->inf] represents the penalty associated with errors larger than epsilon. Increasing cost value causes closer fitting to the calibration/training data.
- gamma: Kernel gamma parameter controls the shape of the separating hyperplane. Increasing gamma usually increases number of support vectors.
- nu: Nu (0 -> 1] indicates a lower bound on the number of support vectors to use, given as a fraction of total calibration samples, and an upper bound on the fraction of training samples which are errors (misclassified).
Examples of SVMDA models on simple data
Example two-variable data (x,y) with 20 samples belong to red class and 20 to blue class. Following images show SVM classification models trained on these data using RBF kernel and varying values for the cost and gamma parameters
- Two-class dataset
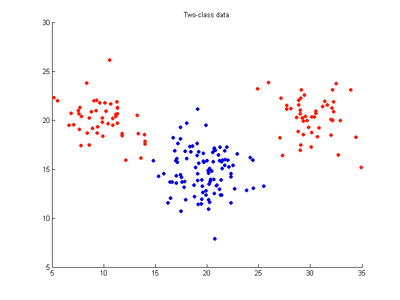
Two-variable data (x,y) with 20 samples belong to red class and 20 to blue class.

- Effect of varying Cost parameter, with gamma = 0.01
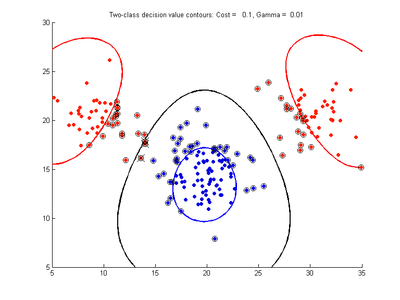
c = 0.1
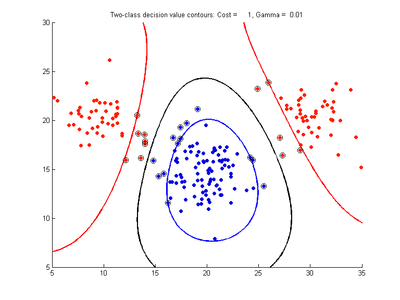
c = 1
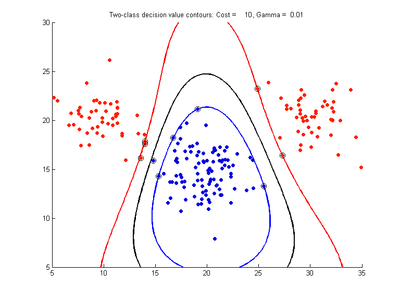
c = 10
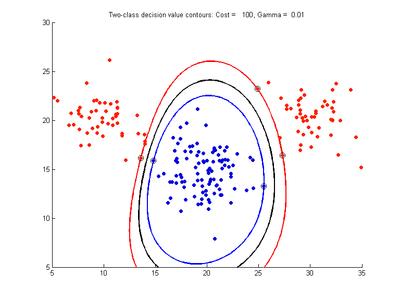
c = 100



